Several cloud cost optimization solutions are today available both by Cloud Providers, such as AWS Compute Optimizer or Google machine type recommendations, and by specialized COTS vendors. These tools may help you choosing the right cloud instance and volume sizes, allocating resources in order to minimize costs over time, and identify the most cost-effective option among multiple Cloud Providers.
Unfortunately, these tools do not ensure that your end-to-end application performance and resilience will be positively affected by recommended changes. They only rely on historical infrastructure metrics (like CPU utilization) and predefined best practices which do not take into account your specific application architecture and scalability. Such characteristics play an important role on how the real application performance will be impacted by changes in the underlying infrastructure, such as compute (e.g. moving to an instance type with a new cheap but lower power AMD processor vs a costly Intel) or storage (e.g. AWS gp2/gp3 vs io1/io2).
Balancing application performance and cost on the cloud is a daunting task. Today even more so, in light of the growing number of instance types available by Cloud Providers and faster release cycles which may prevent application teams from properly optimizing cloud configurations for their applications and thus ensuring that SLOs are matched. However, as we show below, achieving both maximum application performance while also minimizing cloud costs is not an impossible dream.
The approach we advocate for does not simply provide some general recommendations based on historical utilization, but delivers optimal cloud configurations that reduce costs and have been validated with real performance experiments against your actual application.
A world of opportunities…and unexpected costs
Today cloud offerings provide plenty of choices. For example, the following picture from an AWS presentation lists 300+ available EC2 instance types, each one tailored “for virtually every workload or business need”.
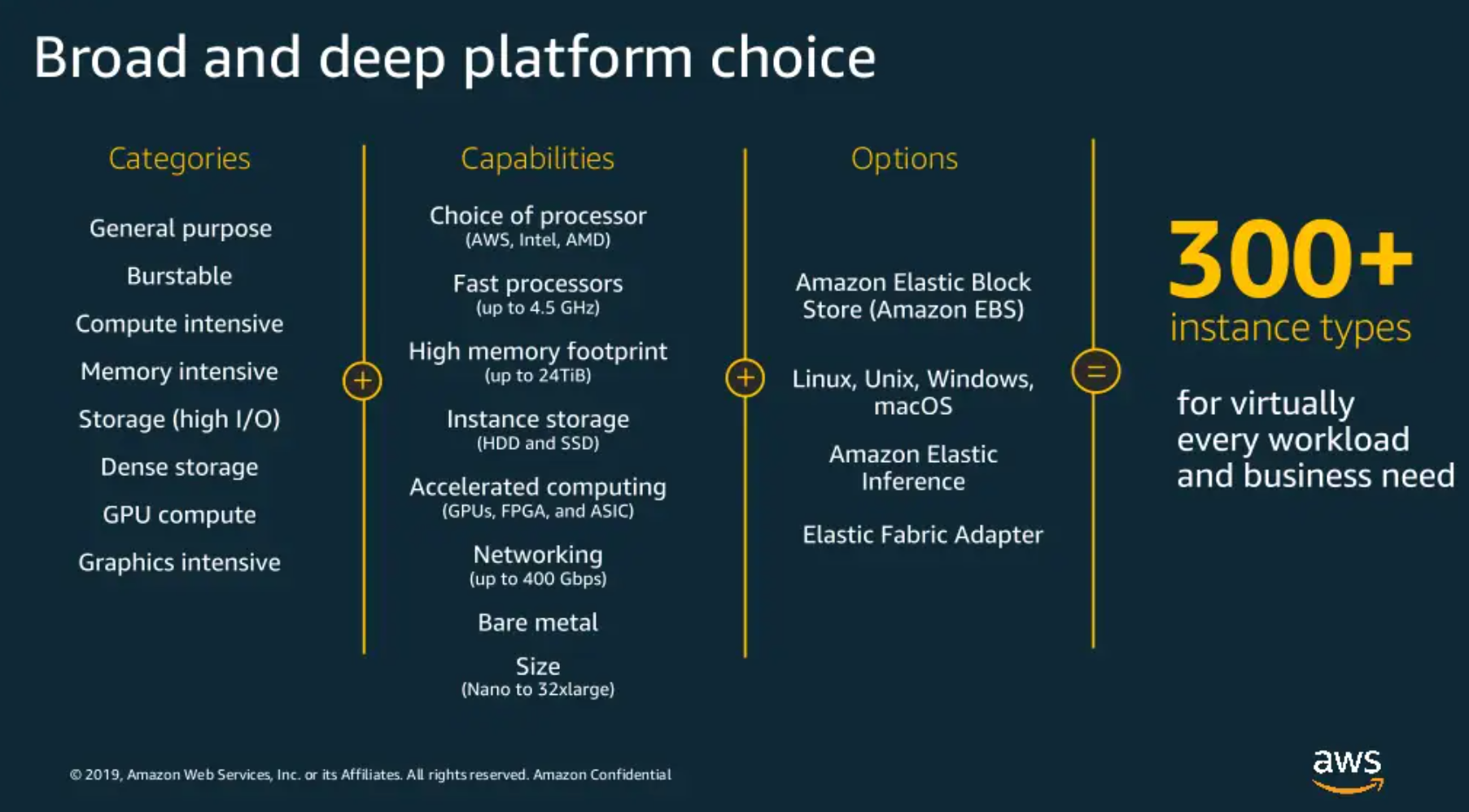
Thus, choosing the right instance translates into selecting the underlying processors and architectures (e.g. Intel Xeon, AMD EPYC, AWS Graviton, etc), how much CPU and memory is needed, which storage (e.g. HDD – either cold or throughput optimized, SSD either general-purpose or provisioned IOPS), not counting special-purpose hardware and networking (e.g. GPU and FPGAs).
This choice is also complicated by the fact that compute instance and storage types are interdependent. If you need higher storage performance, buying a more powerful volume may not be enough as your IOPS or bandwidth may be limited by your instance size. You may need to buy a bigger instance even though the additional compute resources are not required.
Therefore, cloud teams have plenty of choices for building their cloud infrastructure. However, the impact of these choices on the cloud bill can be quite significant. For example, the cost of EC2 instances ranges from a few dollars to dozens of thousands dollars per month (on demand), while the cost of EBS ranges from a dozen dollars to hundreds dollars per 1 TB a month for provisioned IOPS.
The driving factor in selecting the best cloud infrastructure is of course your applications and their specific characteristics – like architecture and scalability – as well as the required performance (throughput and latency) and availability requirements. For example: what is the cheapest EC2 instance to sustain my peak load of 1000 payments per second, while still processing payments within 1 second? Shall I go with blazing fast (and expensive) Intel Xeon processors or are cheaper AMD alternatives enough? And what memory and IOPS do I really need?
Current tools cannot answer such questions, as recommendations only rely on measured resource utilization and some more or less sophisticated models. For example, Amazon has recently released an enhanced version of AWS Compute Optimizer that recommends AWS EC2 instance types by leveraging machine learning techniques to analyze historical utilization metrics such as CPU, memory, network, or disk utilization.
Do these modeling approaches work when application performance is at stake? The general answer is no, they don’t, as even the most sophisticated modeling techniques are unable to identify the hidden bottlenecks and capture the unique application and workload behavior.
This is also confirmed by the Cloud Providers themselves, see for example the official AWS EC2 documentation:
There is no substitute for measuring the performance of your entire application, because application performance can be impacted by the underlying infrastructure or by software and architectural limitations. We recommend application-level testing, including the use of application profiling and load testing tools and services.
So, when cloud costs and service quality are critical, performance tuning is a must. However, the sheer complexity of cloud environments and the accelerated pace of application releases make any manual approach infeasible.
That is why an entirely different approach is required.
Performance-aware cloud optimization – it is not a dream
To illustrate how the AI-driven cloud optimization approach works, we consider an application based on a MongoDB database hosted on the AWS cloud. In this case, the customer goal was to maximize the cost efficiency, that is to find the AWS compute and storage types minimize the price/performance ratio:
- Price is the monthly cost for the cloud resources;
- Performance is the maximum application throughput (queries/sec) that the application can achieve with a specific AWS EC2 and EBS configuration.
To match this requirement, we leveraged our Akamas platform that allows us to automatically drive a series of automated experiments and take advantage of its AI-based optimization based on custom-defined goals. Moreover, Akamas native integration with AWS pricing APIs allows the optimization goal to be directly formulated in terms of cost associated with each instance type and EC2 and EBS options.
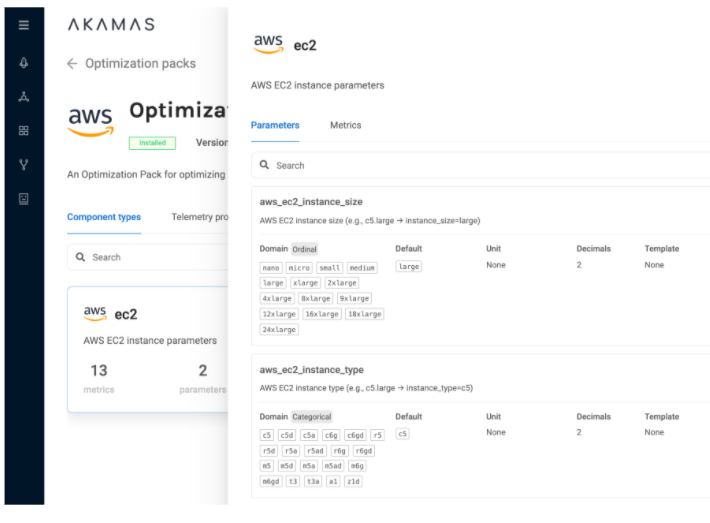
In each experiment, a specific AWS EC2 and EBS configuration, identified by the AI engine as a good candidate for improving the cost efficiency, was automatically provisioned and tested. The real application performance (queries/sec) achieved was measured from the load testing tool.
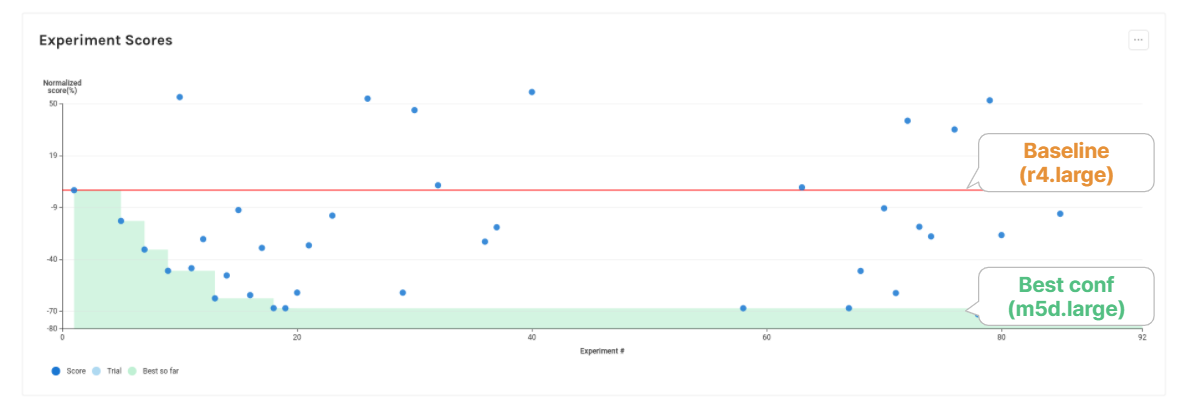
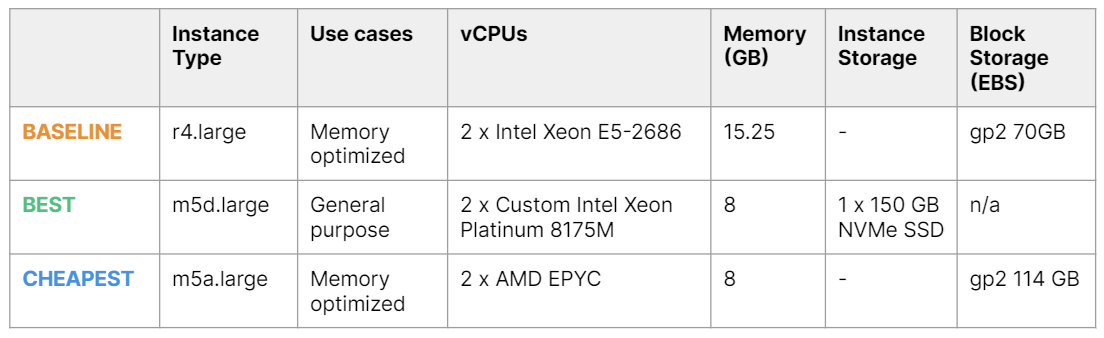
The initial (baseline) configuration for the database was a r4.large EC2 instance with gp2 70 GB EBS volume – a common choice for memory-intensive database workloads (see AWS recommendations).
The optimization study started providing good results in a relatively short time (see the following figure). After only 18 experiments, in approximately 22 hours, a configuration providing a 68% improvement of the cost/performance over the baseline was identified.
This configuration (see the following figure) has a similar cost (it is just a bit cheaper: -3%) but triples the performance (+205% throughput) over the baseline. Plus it also slightly reduces the latency (-90%), which is an interesting and unexpected result as latency had not been included in the original goal.
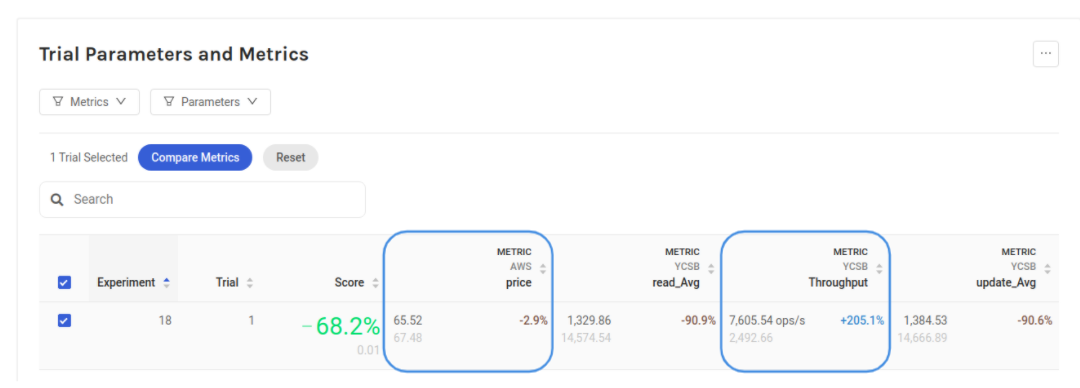
To better understand these results, let’s have a closer look at this configuration by comparing it to the baseline configuration (see the following figure).
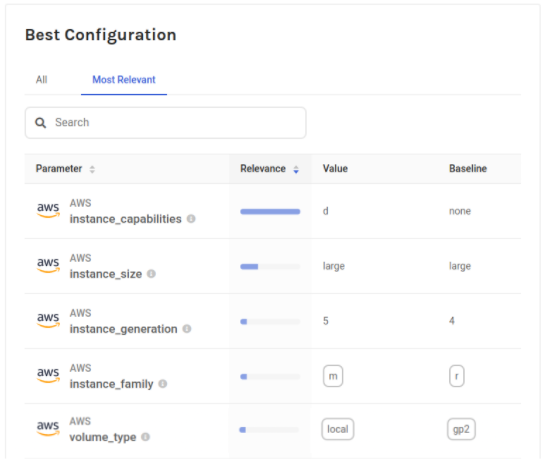
The instance type in this best configuration is m5d.large, which is unexpected as M5 is a general-purpose instance, while the baseline r4.large instance is memory-optimized and as such should be more suitable for databases.
But there is more.
The best configuration has only half of the memory, which shows that having more memory was not benefiting the database throughput.
What about storage? The best configuration uses a locally attached storage, which of course helps bring down the cost. However, this may not represent an acceptable option as losing the instance would also imply losing the database itself with all data. Indeed, EBS storage, which gets replicated to different Availability Zones, is typically recommended for databases. This additional constraint could have been set right from the beginning, but in this first study it was decided to not apply any restriction and be able to evaluate all options.
Even if we restrict to only EBS storage, a better configuration than the baseline can be identified. A configuration corresponding to m5a.large instance is both cheaper (-24%, as relying on an AMD processor) and more performing (+12% throughput).
The following table summarizes the results of the optimization study.
This case shows that it is actually possible to pursue the goal of reducing the cloud bill while ensuring (actually even improving) application performance.
Conclusions
We argue that cloud optimization should be pursued by not only focusing on reducing the cloud bill but also taking the end-to-end application performance into account.
This is a requirement that cannot be supported by most of the available cloud optimization tools, as they rely on historical infrastructure utilization and on more or less sophisticated modeling techniques that may fail to identify the hidden bottlenecks and capture the unique application and workload behaviour.
The new approach leverages specialized AI techniques that are able to smartly explore thousands of configurations, including the hundreds of configurations associated with cloud instance types, in just a few hours. Thanks to Akamas, Performance Engineers can identify the optimal configurations with respect to their specific performance and cost tradeoffs goals and constraints (e.g. SLOs).
Keep reading our blog and learn more real-world stories about how to optimize cloud-based and other applications. Stay tuned!

Author:
Luca Chiabrera
Head of Customer Success and Sales Engineering