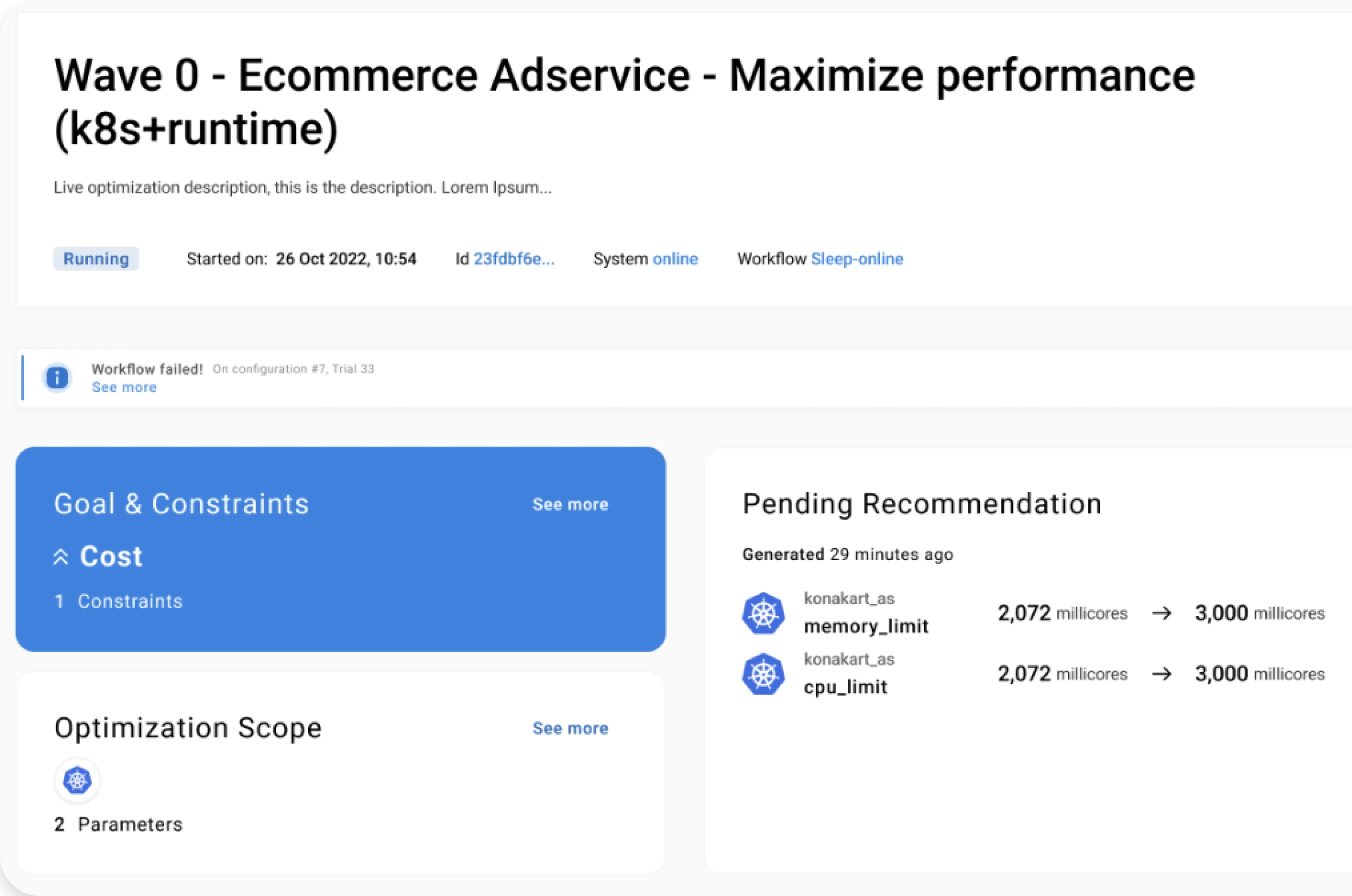
Based on my experience with customer environments, my top three required capabilities are: 1) ability to define goals and constraints (such as SLOs), 2) ability to operate full-stack, in particular to incorporate both the application runtime and container layers and 3) safety.
First of all, different optimization goals are required for different applications, and also for the same application, at different times. Today the goal might be to make my application capable of processing more orders, while tomorrow it might be to save costs, while ensuring response time SLOs.
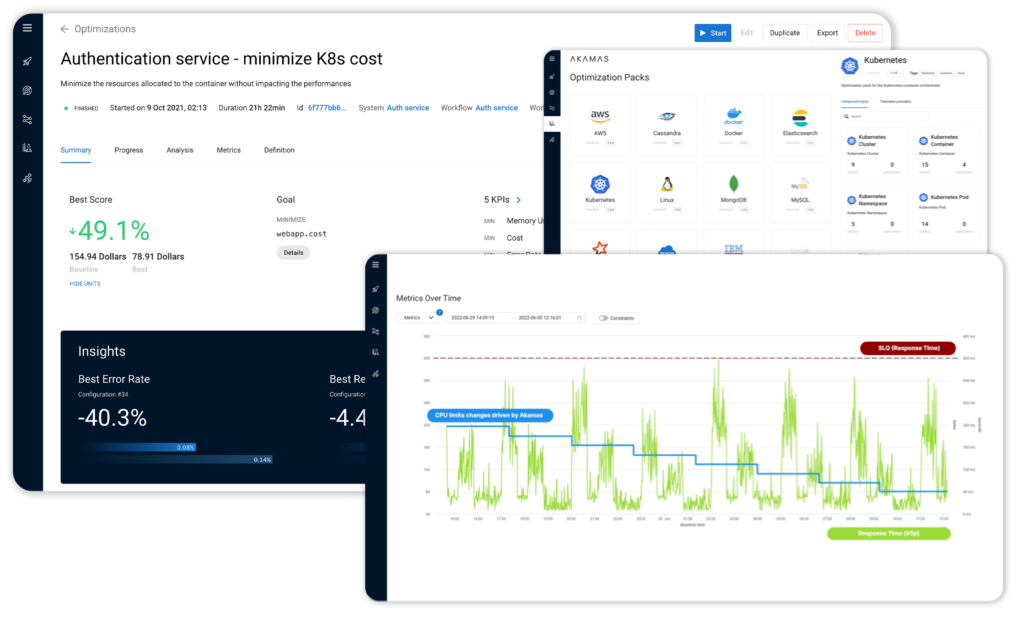
Tools that only support pre-defined optimization goals, such as cost reduction, and that do not allow users to specify custom optimization functions and metrics, are not suitable for the real-world.
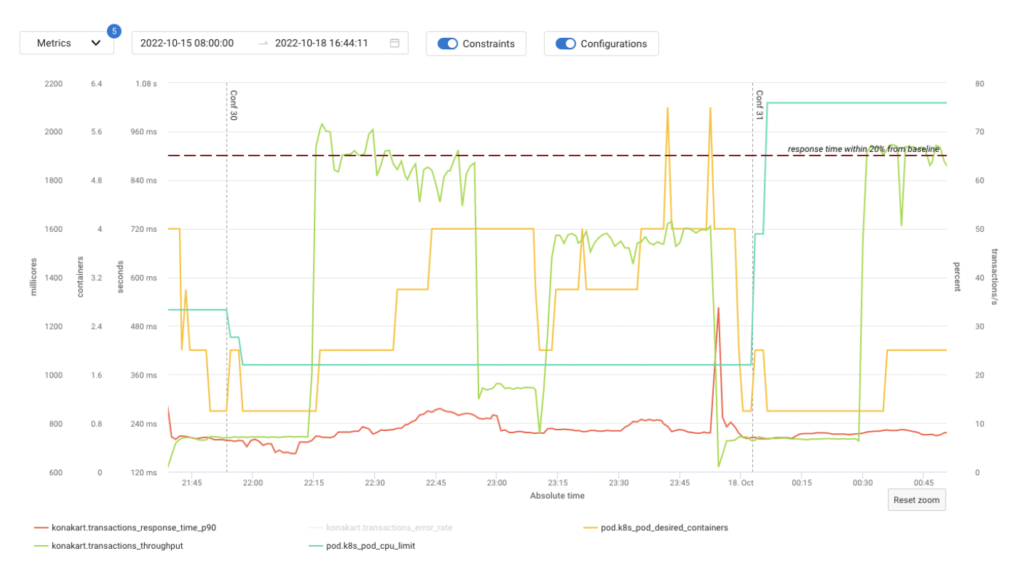
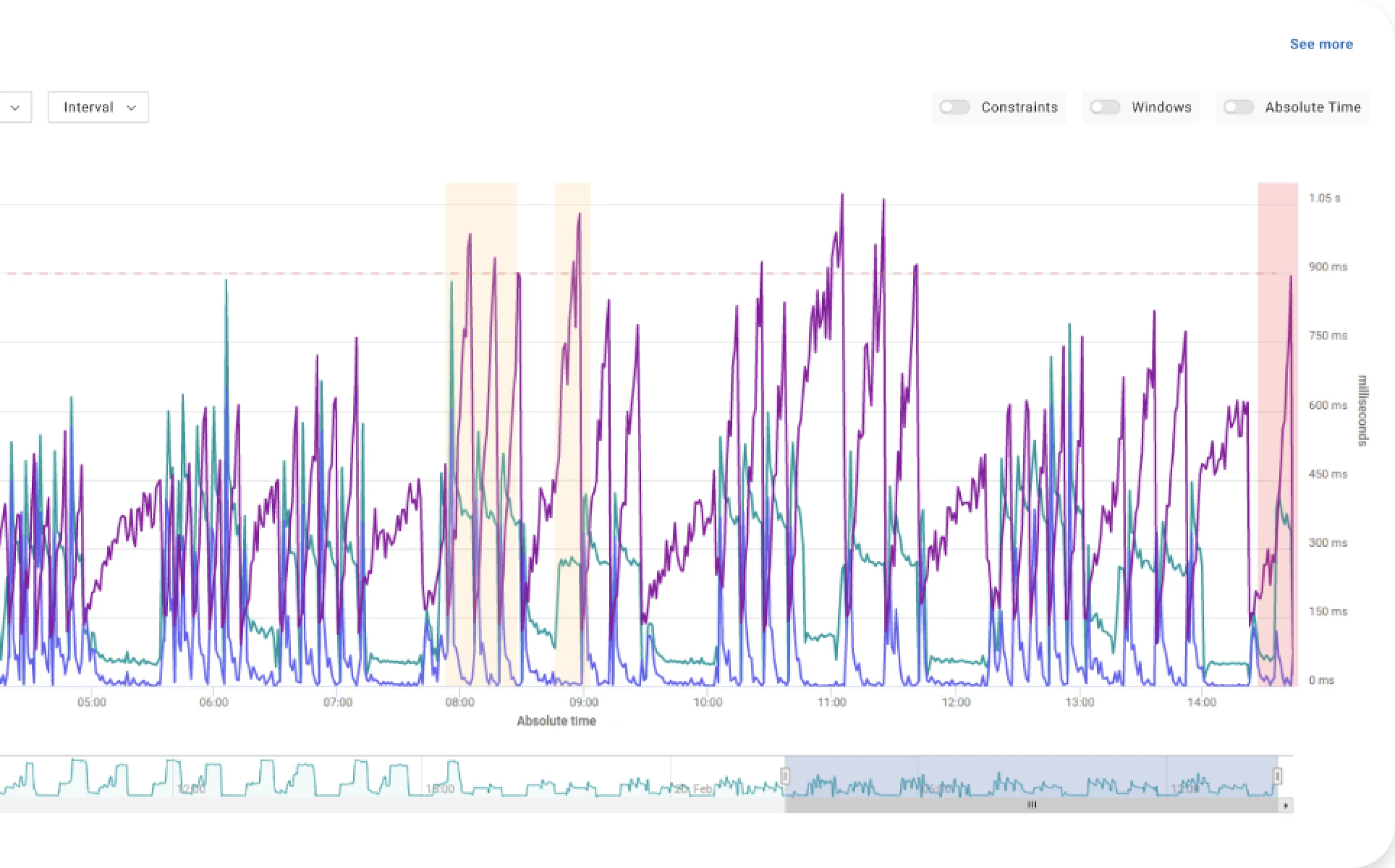
Similarly inadequate are tools that only provide indicators of how SLOs have been impacted only after changes have been applied, without taking them into account when looking for the optimal configuration.
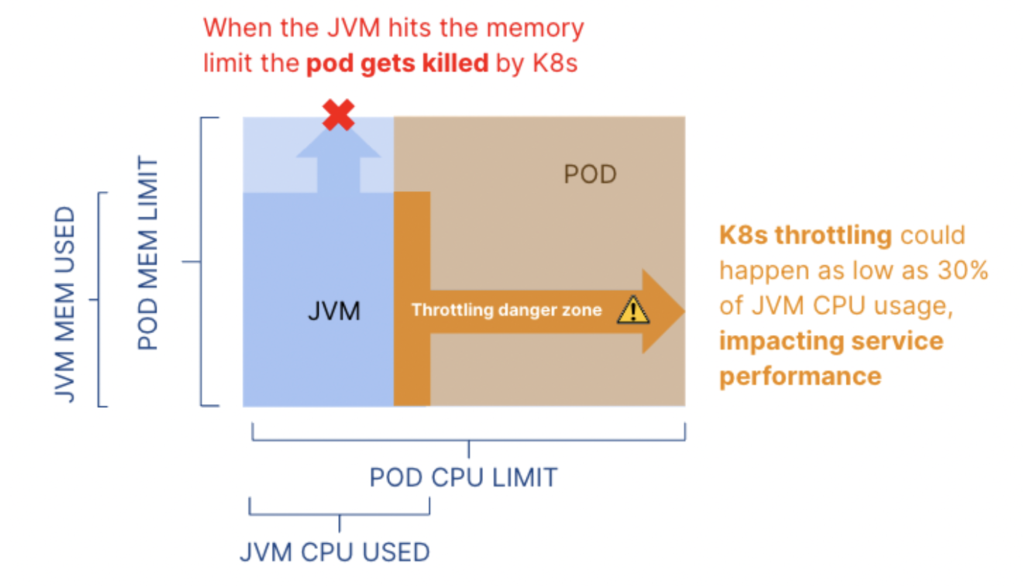
Second. Ideally, recommended configurations include parameters at the different layers of the application and the underlying infrastructure. As we see again and again, for Kubernetes microservices applications, it is imperative that both the runtime and container layers are considered.
Let me re-emphasize this point: this is not just to take advantage of opportunities to improve cost efficiency and performance, but to prevent major availability and performance risks. So, customers should be very careful when selecting tools that only focus on the infrastructure or operate only at the container level.
Lastly, safety is a major topic as when you are optimizing applications in a production environment, with dynamically varying workloads and unexpected issues, safety is not a nice-to-have. This is a major research area for us, which we started working on quite some time ago, and that led us to introduce safety policy features such as gradual optimization, smart constraints and outlier detection. For those interested, we have some materials on our website.