The benefits of Kubernetes from a performance perspective are undisputable. Let’s just consider the efficiency provided by Kubernetes, thanks to its ability to densely schedule containers into the underlying machines, which translates to low infrastructure costs. Or the mechanisms available to isolate applications from each other, thus preventing that a runaway container might impact critical service performance.
Given the increased level of adoption, it is not surprising that the Kubernetes spending is growing as reported by the Kubernetes FinOps Report (June 2021) survey, even if it makes you wonder whether this may also reflect to some degree the known challenges of making Kubernetes cost-efficient.
However, not everything is shining bright in Kubernetes-land. As a matter of fact managing application performance, stability, and efficiency on Kubernetes is a tough job even for the most experienced Performance Engineers and SREs. The Kubernetes Failure Stories website, which was created with the purpose of both sharing Kubernetes incident reports and learning how to prevent them, provides many stories describing how teams are struggling with Kubernetes application performance and stability issues, such as unexpected CPU slowdowns and even sudden container terminations.
In the following, we first explain the key reasons is how Kubernetes manages resources which requires applications to be carefully configured to ensure cost efficiency and high performance. Then, we also describe how our ML-based optimization provides an effective approach to take this challenge, by applying it to a real-world application.
Back to Kubernetes fundamentals: resource requests and limits
To better understand the challenges of managing Kubernetes, we need to review how Kubernetes resource management works and its impact on the application performance, stability, and cost-efficiency.
The first important concept is resource requests.
When a developer defines a pod in a Pod Manifest, they can specify the amount of CPU and memory that pod (or better, a container within the pod) is guaranteed to get. Kubernetes will take care of scheduling the pod on a node where these requested resources are actually available.
In the example illustrated by the following figure, Pod A requires 2 CPUs and is scheduled on a 4 CPU node. When a new Pod B of the same size is created, it can also be scheduled on the same node. This node now has all of the 4 CPUs already requested. So, Kubernetes will not schedule another pod (let’s say Pod C) on this node as its CPU capacity is already full.
Therefore, pod resource requests in Pod Manifests are used by Kubernetes to manage real cluster capacity.
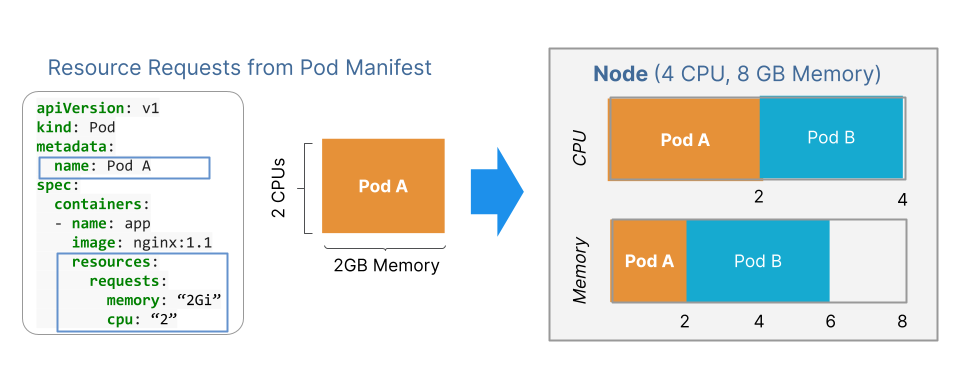
Since with Kubernetes, there is no overcommitment on resource requests, you cannot request more CPUs than those available in the cluster. This is very different from virtualization, where you can create VMs with many more virtual CPUs than the real physical CPUs. Moreover, resource requests are not equal to resource utilization. So, if pod requests are set much higher than actual resource usage, it is possible to end up with a cluster that is full even though its resource utilization is very low (e.g. CPU at 10%).
As a consequence, setting proper pod resource requests is paramount to ensure Kubernetes cost efficiency.
The second important concept is resource limits.
Resource requests are the guaranteed resources a container gets, but resource usage can be higher. So, resource limits is the mechanism that can be used to define the maximum amount of resources a container can actually use. For example, Pod A could have 4 CPUs and 4 GB of memory as resource limits.
The following figure shows that Kubernetes treats CPU and memory very differently in case resource usage hits these limits.

When CPU usage approaches limit, the container gets throttled. This means access to CPU resources is artificially restricted, which can cause application performance issues. Instead, when memory usage hits the limit, the container gets terminated by Kubernetes. There is no application slowdown due to paging or swapping as in traditional operating systems. With Kubernetes the pod simply disappears, which can cause serious application stability issues.
However, with CPU limits there is an important and less known effect that can have a heavy impact on application performance.
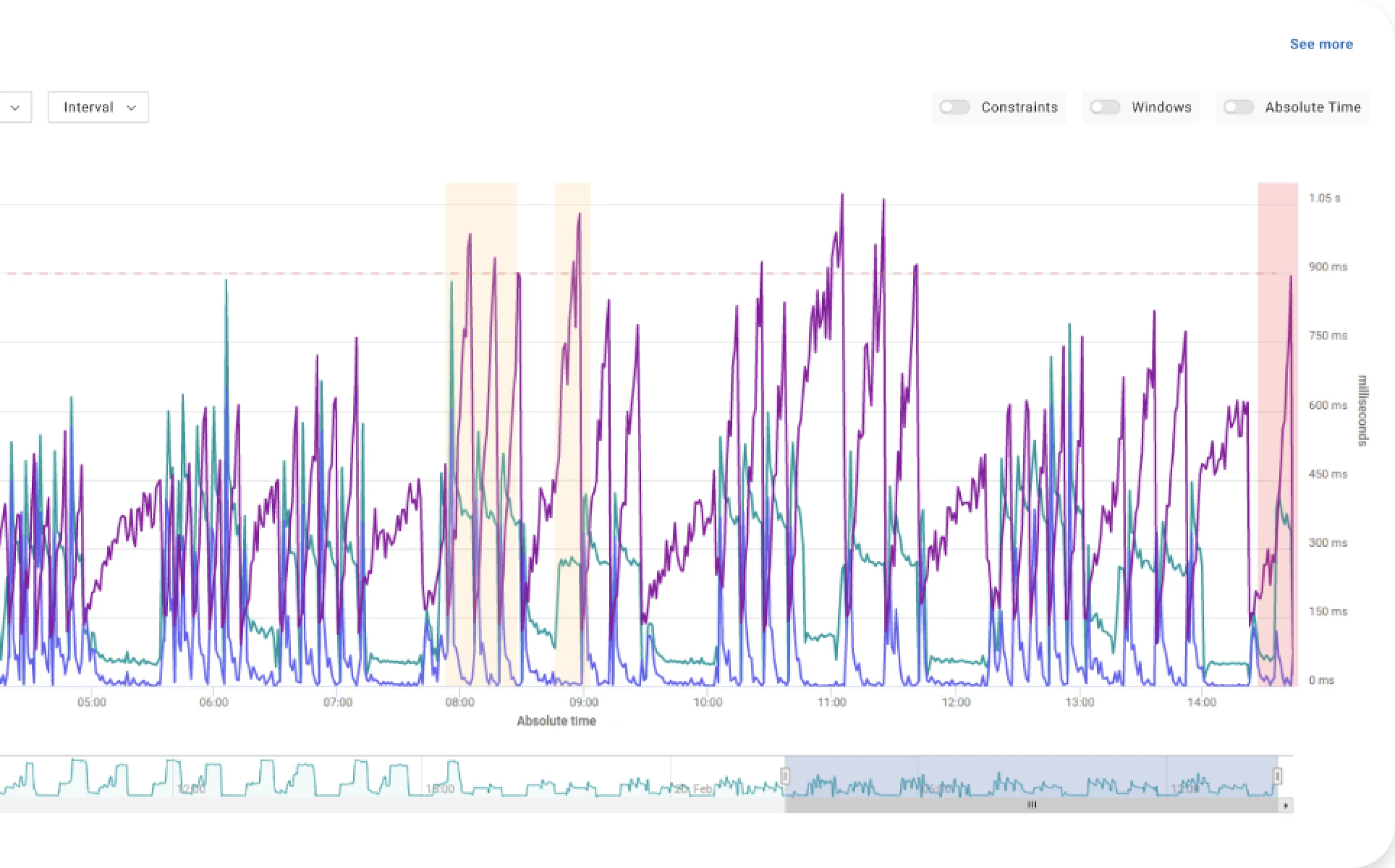
Indeed, CPU throttling is not only triggered by CPU usage hitting the limit but already starts when CPU usage is well below the limit. In the Akamas labs, we found that CPU throttling can start when CPU usage is as low as 30% of the CPU limit (see following figure). It may be worth mentioning that this effect is due to the particular way CPU limits are implemented at the Linux kernel level.
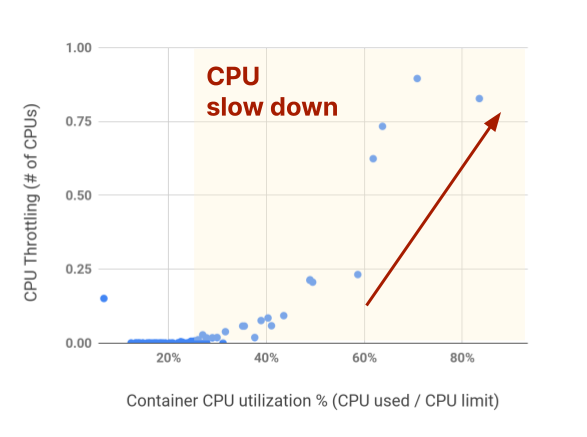
This aggressive throttling has a huge impact on service performance: we could get sudden latency spikes that may breach SLOs without any apparent reason, even at low CPU usage.
However, it is not a good idea to remove CPU limits. By doing so, we might get an impressive reduction of service latency (e.g. see results achieved at Buffer), but a single runaway application could completely disrupt the performance and availability of our most critical services. This is why setting the resource limits is the recommended best practice by Google.
Therefore, properly setting CPU requests and limits is critical to ensure that Kubernetes clusters remain stable and efficient over time. However, due to how Kubernetes manages container resources, it is not easy to tune Kubernetes.
When considering that cloud-native applications are typically made of dozens of microservices, the challenge of optimizing Kubernetes applications seems a mission impossible job: “properly set resource requests and limits for all microservices, also taking into account autoscaling and application settings like JVM options, to ensure that the overall application meets its performance and availability requirements and SLOs, at minimum cost”.
The good news is that it is actually possible to get this job done, when a new approach is taken.
Optimizing Kubernetes automatically
The approach we took at Akamas was to leverage ML-based optimization techniques known as Reinforcement Learning that make it possible to smartly explore huge combinatorial spaces of possible configurations in a relatively short time. With Akamas, the process of identifying the optimal configuration is fully automated and is based on whatever goals and constraints you want to set. At each experiment, a candidate configuration suggested by ML is applied, and the results are used to learn how to converge to an optimal configuration.
To illustrate how this approach works, we consider the Google Online Boutique, a cloud-native application running on Kubernetes made of 11 microservices written in Golang, Node.js, Java and Python. It also includes a load generator based on Locust, which generates realistic traffic to test the application. In our setup, we also leverage Prometheus and the Istio service mesh, respectively to gather pod resource consumption metrics and service-level metrics.
For this application, we aim at maximizing its efficiency, that is both increasing the service throughput and decreasing cloud costs, while also ensuring that SLOs are met. The following figure shows how the corresponding optimization goal and constraints are defined with respect to the metrics associated with the Online Boutique components.
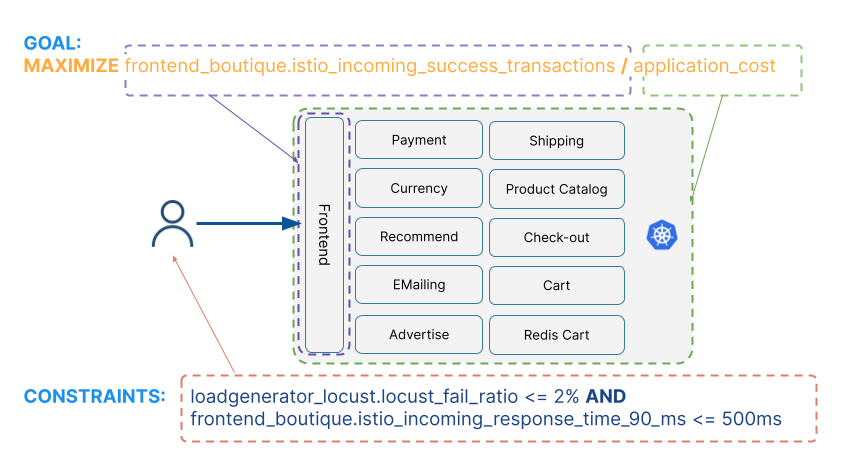
As illustrated by the previous figure, the optimization goal is set to maximize the ratio between service throughput, measured at the frontend layer, where all user traffic is processed, and overall cost, calculated by the Cloud Provider based on the CPU and memory resources allocated to each microservice. In our study, we considered AWS Fargate, a serverless Kubernetes offering that charged 29$/month for each CPU requested and about 3 $/month for each GB of memory (updated pricing is available here). The constraints are set to only accept configurations that are associated with a 90 percentile latency not higher than 500ms and to an error rate lower or equal than 2%.
Since in this simple optimization study we only focused on Kubernetes [notice: more complex studies also including other parameters will be discussed in following blog entries], the tunable parameters are represented by the CPU and memory limits of each microservice, for a total of 22 tunable parameters.
The ML-optimization was able to automatically identify in just 35 iterations, about 24 hours, a configuration that improved the application cost efficiency by 77%, from 0.29 TPS/$/mo (baseline) to 0.52 TPS/$/mo (best configuration).
The (partial) results of the ML-based optimization approach are illustrated by the following figure, where the initial configuration for the CPU and memory limits (baseline) are compared to the best configuration.

It is worth analyzing the adjustments to resource limits produced by this best configuration. Indeed, several microservices got their CPU limits reduced, which clearly represents a winning move from a cost perspective. However, two microservices were underprovisioned, by increasing both their assigned CPU and memory. As a matter of fact, all these changes at the microservice level are critical to achieve the goal of improving the level of service (i.e. maximizing throughput) and lower cost, while also matching the defined constraints.
The following charts compare the overall service performance, respectively in terms of throughput (left) and 90 percentile response time (right), when the best (green lines) and the baseline configuration (blue lines) are applied.
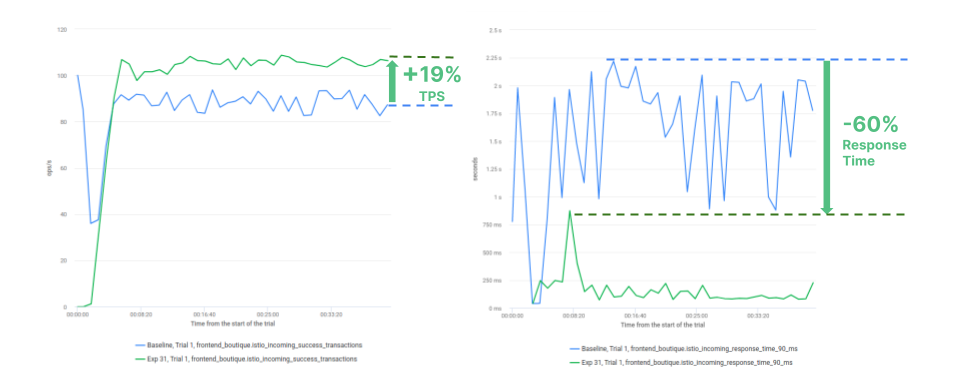
These charts demonstrate that the best configuration, besides being much more cost-efficient, also improves the application throughput by 19%, cuts the latency peaks by 60% and makes the service latency much more stable.
Conclusions
Kubernetes is a great platform to run microservice-based applications, but it also requires applications to be carefully configured to ensure cost efficiency and high performance. As we have discussed, tuning these applications is a daunting task even for the most experienced performance experts, in particular due to the complexity of how Kubernetes manages resources.
Traditional approaches mostly relying on manual tuning cannot consistently guarantee that the desired application performance, stability, and cost-efficiency are achieved. The specialized AI techniques we use at Akamas are able to smartly explore thousands of configurations, including the hundreds of configurations associated with each microservice, in just a few hours.
Thanks to Akamas, Performance Engineers, SREs and Developers can identify the optimal configurations with respect to their specific performance and cost tradeoffs goals and constraints (e.g. SLOs).
Keep reading our blog and learn more real-world stories about how to optimize cloud-based and other applications. Stay tuned!

Author:
Stefano Doni
Co-founder & CTO