Big data applications often offer relevant opportunities for gains both in terms of performance and of cost reduction. Typically, the underlying infrastructure – whether on-premise or on cloud – is both inefficient and over-provisioned to ensure a good performance vs cost ratio.
While several best practices are available from vendors, configuring and tuning big data applications remains an extremely difficult job. The main challenge is represented by the fact that their performance and reliability are very sensitive to both the specific application and the applied datasets.
Additional challenges for Data Scientists, who typically develop and manage these applications, are the level of skills and expertise required for tuning the lower layer of the stack, and the fact that performance tests are rarely applied in environments that are representative of the real production.
To illustrate how to address these challenges with a different approach, in the following we consider a real-world case where Spark configuration and AWS Elastic Map Reduce (EMR) resources were automatically tuned to reduce the cloud bill, which also delivered a shortened job execution time.
Big data and big challenges
A first challenge is represented by the overwhelming number of available parameters. About 200 parameters only at Spark level plus about another 200 parameters at Cluster Manager level – corresponding to thousands of possible configurations to pick from when releasing to production. This is also because Spark default settings are not meant for production environments, as clearly stated by Karau and Warren in their book ”High Performance Spark”.
Spark’s default settings are designed to make sure that jobs can be submitted on very small clusters, and are not recommended for production.”
H.Karau, R. Warren – High Performance Spark
A second fundamental challenge is represented by the data-driven nature of big data architectures which makes their performance (and reliability) highly sensitive to both the specific application and datasets:
- When the input data changes over time, data may need to be re-partitioned differently across worker nodes to avoid out-of-memory situations;
- New application release may change how the data flows in the application, thus making any previously identified tuning not applicable anymore;
- Production environments often differ from test environments, thus tuning needs to be done directly in a production environment.
Therefore, it is extremely difficult to define universal rules or even general best practices on how to maximize Spark performance.
This situation is clearly summarized in the ”High Performance Spark” book.
Configuring a Spark job is as much an art as a science. Choosing a configuration depends on the size and setup of the data storage solution, the size of the jobs being run (how much data is processed), and the kind of jobs.
H.Karau, R. Warren – High Performance Spark
A third challenge is represented by Spark jobs not always running on premise clusters, as today cloud providers offer attractive options that make cluster management cheaper and more aligned to fluctuating demand.
Adopting the cloud option also implies even more options to choose from. For example, AWS Elastic Map Reduce (EMR) provides about 230 combinations of instance families and sizes, each one with its own characteristics and whose performance has to be balanced against the corresponding cost.
Therefore, it seems that the general complexity of doing performance tuning in today’s modern architectures reaches its highest level for big data applications.
So, is big data optimization an impossible problem to solve?
A real-world big data application
The case study here is a critical Digital Media service serving about 1 million users per day. This service is based on a Business Intelligence application that analyzes content fruition from online stores, streaming services or news sites. On average, 25 million events per day are collected, transformed, and aggregated from raw logs and user transactions. Each event represents a user interaction, such as browsing, searching, accessing, and consuming (a portion of) content from the catalog.
The core component is the Analytical Engine (see the following figure), a Spark batch running several times a day on an ephemeral EMR cluster.
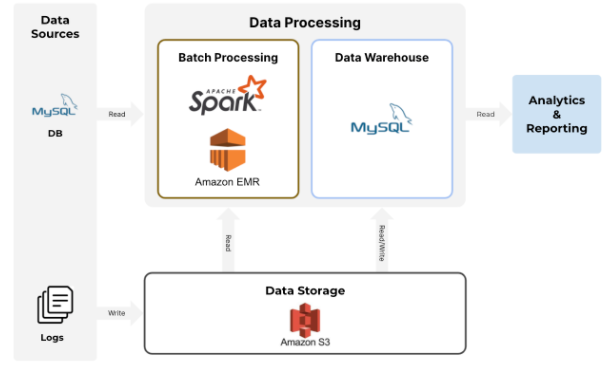
The customer was facing long execution times even if the cluster had been overprovisioned, and higher than desired cloud bills.
Preliminary performance analysis showed that the application displayed a very low level of parallelism as only a fraction of all the available executors (11) were performing useful computations. This was likely due to an imbalance in the distribution of the data, which for most of the batch was leaving the majority of the executors stalled, waiting for the completion of the few ones that were performing useful computations. This problem could have possibly been addressed at code level, but there was an urgent need for reducing the cloud cost without waiting for a complete reengineering of the application.
Two major areas of optimization had been identified, respectively at AWS cluster and Spark level:
- Identify the right size and configuration of the AWS cluster, by balancing allocated resources and execution time, and also verifying whether it would be more convenient to run a few big instances or many small ones;
- Find the right Spark and YARN configuration that maximizes the performance while ensuring that each batch would (successfully) terminate within 4 hours, that is before the next batch would run.
Operating on these two potential areas of optimization was not easy for the customer due to the complexity of the environment, the amount of data to be processed, short time available to do some (if any) performance tuning, and lack of adequate skills on how to select cloud instances in this context.
Let an optimal Spark and EMR configuration to be found
We approached the problem by making no assumption on which configuration options were worth exploring, by letting Akamas patented AI to automatically search for an optimal configuration. The optimization goal was to reduce the cloud bill, with the constraint of not increasing the execution time by more than 50%.
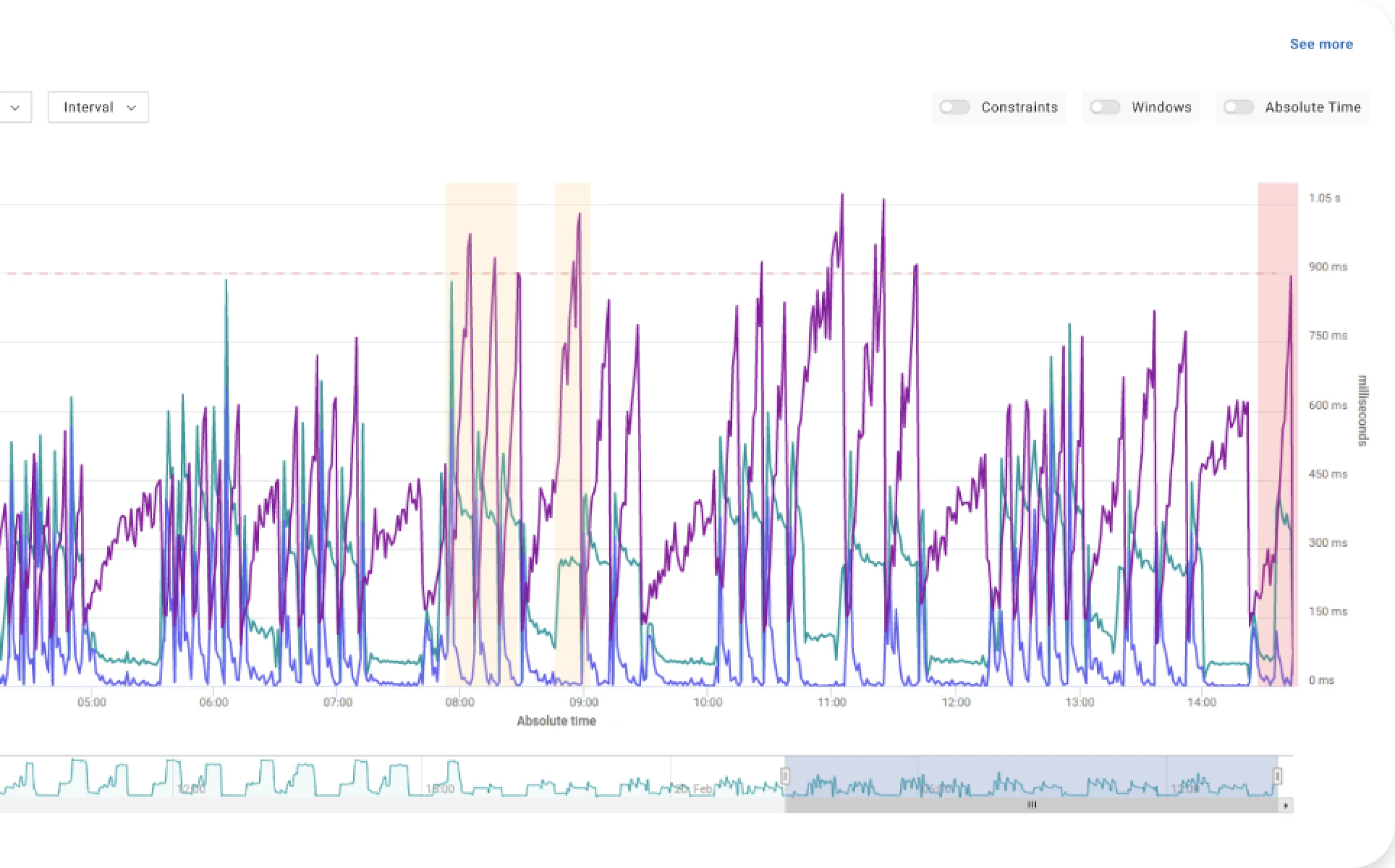
The following figure shows the progress of the study, where each blue dot corresponds to an experiment, that is to a set of Spark and EMR parameters. The yellow bands in the chart correspond to “failed” configurations, as either not completing successfully or not matching the constraints. Akamas automatically leverages these “failures” to further prune the search.
The first experiment (aka “baseline”) corresponds to the initial configuration while the following experiments correspond to each configuration identified by Akamas AI as the best next candidate based on the results from previous ones.
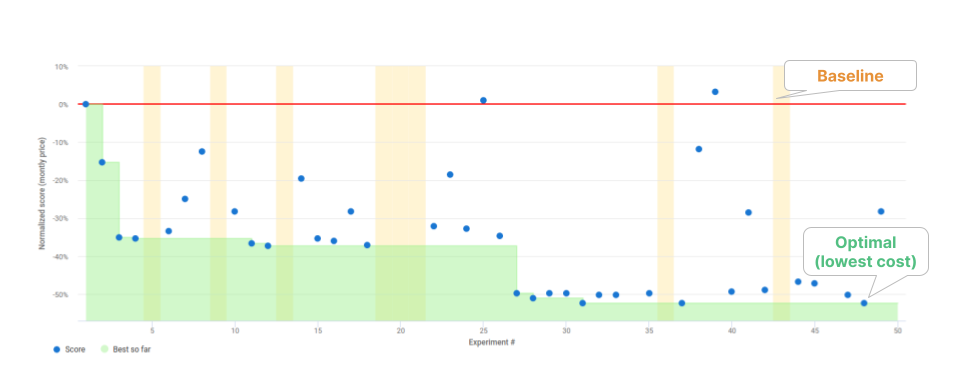
Notice that most of the configurations have lower scores (i.e. lower cost) than the baseline, which confirms that the cluster had been overprovisioned.
Overall, 50 experiments were executed. Some better configurations were already identified within the first 24 hours, until at experiment #27, in about 3 and half days, Akamas converged to a much cheaper configuration (-52%).
Let’s analyze this configuration (see the following figure).

Both the instance associated with the master node and worker nods as well as the number of worker nodes themselves was changed:
- Master node was scaled down from a m5.4xlarge instance to a m5.xlarge instance – about one-fourth of the initially allocated resources – this is because the master node is used by base Spark services, not for core computation;
- Worker nodes were reduced from three smaller (m5.4xlarge) to one larger (m5.8xlarge), about 33% reduction – this does not align to the general guidance about having multiple small nodes, but it is justified since this application does not fully take advantage of massive parallelism;
- Additional resources (from 3 to 5 CPUs, from 17 to 32 GB) were allocated to the driver.
It is also interesting to look at the aggregate cluster CPU and memory utilization for the baseline (orange line in the figure below) and optimal configuration (green):
- The optimal configuration has a higher average CPU usage – thus a better utilization of the allocated CPUs;
- The optimal configuration uses less memory (-17% peak memory usage) – which provides headroom for the application to be more resilient.
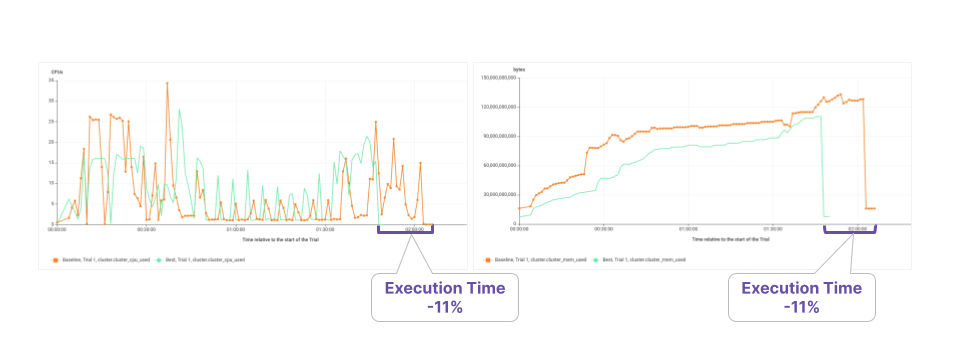
There is another interesting benefit of this configuration which is highlighted in the previous figure. The overall execution time is reduced by 11% – which had not been explicitly set as the optimization goal, but is somewhat expected as reducing the uptime of the cluster has obvious benefits in terms of cost.
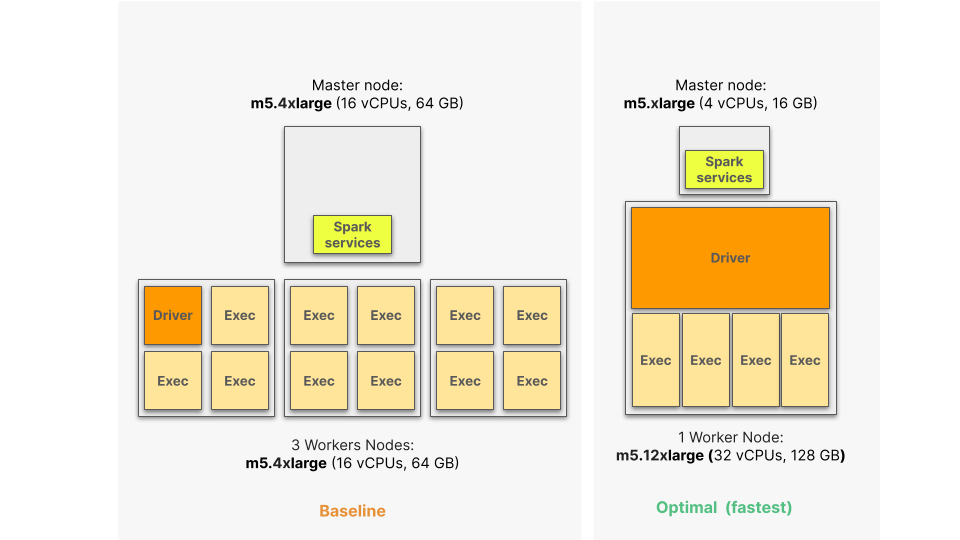
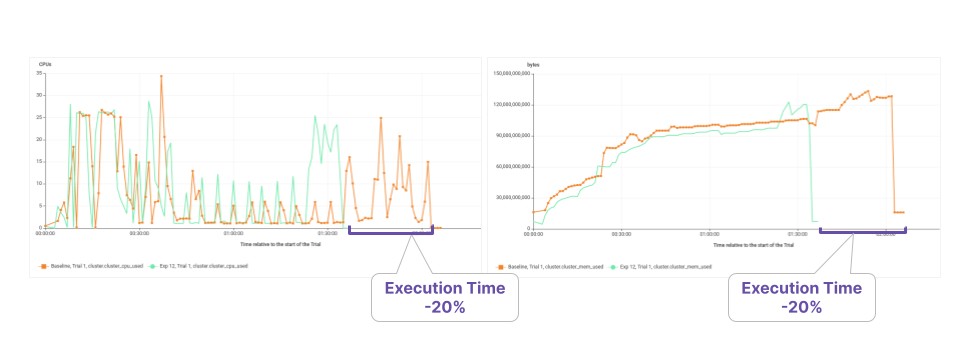
If we set the goal to minimize the execution time, then the optimal configuration (see previous figure) corresponds to an even bigger instance (m5.12xlarge) with one additional executor and a much larger driver. This configuration (see following figure), reduces the execution time by 20% while still providing a relevant (-37%) cost-saving.
Conclusions
Configuring and tuning big data applications is an extremely difficult job even for experienced Performance Engineers and Data Scientists. Nevertheless, it can be tackled easily and quickly, when the right approach and tool are adopted.
Akamas supports a fully automated optimization process where workflows can be customized so as to execute experiments in a completely unattended fashion: a workflow can provision clusters, submit Spark jobs, and collect KPIs and cost metrics required to score that configuration against the defined goal.
Thanks to Akamas patented AI techniques, once the specific optimization goals (e.g. performance vs cost ratio) and constraints (e.g. SLOs) are defined, an optimal configuration of Spark and EMR parameters is automatically identified in a relatively short time even for complex applications.
Keep reading our blog to learn more real-world stories about how to optimize big data applications – and other types of applications.
Stay tuned!

Author:
Luca Cavazzana
Software Engineer