This blog is co-authored by Kyle McMeekin, Head of Channel at Gremlin.
Today’s enterprises are struggling to cope with the complexities of their environments, technologies, and applications. On top of these challenges, they face faster release rates, and the need to always deliver the highest level of performance and availability to end-users, at the lowest possible cost.
Chaos Engineering
In this context, Chaos Engineering has emerged as an effective practice to proactively identify problems before they actually occur. By intentionally injecting failure in controlled experiments (also known as “attacks”), SREs can verify if their failback and failover mechanisms in place do actually work, uncover unexpected problems, and learn how systems work to make them more robust.
By taking a controlled, deliberate, and secure approach with these attacks, enterprises can understand which services contain critical dependencies, reduce noise within their alerting and monitoring solutions, and ultimately, focus on more strategic goals. Using Chaos Engineering ultimately allows organizations to build resilience into the lifeline of their businesses.
Gremlin is the company that has been most successful in industrializing this proactive approach to support companies in making resilience a core part of their DNA. Gremlin features a wide range of attack techniques that can be applied at different layers of the targeted infrastructure, such as consuming resources, delaying or dropping network traffic, shutting down hosts, stopping processes, and many more.
While Chaos Engineering practices can be applied to any environment, an area of growing adoption are cloud-native applications. Resilience and failover capabilities are among the strongest features of Kubernetes, the world’s leading cloud-native container orchestration tool. Nevertheless, reliability was mentioned in a recent survey as one of the top challenges to adoption by 12% of companies using containers and orchestration tools.
Reliability is just as important as performance and this is proven in the work combining Chaos Engineering and Performance Engineering. It is worth noting that several enterprise Load Testing solutions (e.g. LoadRunner) have recently released integration with Gremlin to support the ability to drive failure scenarios when testing systems performance and scaling with respect to the desired customer (e.g. SLOs) or business goals.
Autonomous Optimization
Once Chaos Engineering has identified failure scenarios that may affect the business, the challenge is to prevent these problems from occurring or, at least, mitigate their impact. Depending on the specific application, this may involve adding more infrastructure resources, modifying the architecture, or better tuning the application and its underlying layers. Interestingly, the recent Gremlin’s State of Chaos Engineering study shows that for more than half of the customers, wrong configurations account for at least 20% to more than 80% of their sev0/sev1 incidents.
Unfortunately, tuning today’s complex applications is becoming an increasingly challenging task, even for experienced performance engineers due to the huge number of tunable parameters at each underlying layer and instance options from cloud providers. Adding to the complexity, are the counterintuitive behavior and interplay between these parameters, under specific workloads, that can make vendor defaults and best practices ineffective or, worse, negatively impacting the overall application performance and resilience. The reduction of the release cycle due to DevOps practices does not help either.
A striking example is provided by cloud-native applications. In several Akamas polls, 33% of customers have reported that ensuring the performance and resilience of Kubernetes applications remains an unmet challenge. According to a provider of critical SaaS services, tuning a single microservice (among the hundreds a real-world application is typically composed of) may require several weeks (up to 2 months) of effort. Whether the end goal is to avoid overprovisioning and reduce cloud costs, or to increase the quality of services delivered to users, a simple manual (or automated) tuning is not an effective approach anymore.
This is where another new practice, Autonomous Optimization, can support performance engineers and SREs to automatically identify the best configurations, at business speed. This new practice is supported by solutions that harness the power of AI techniques to explore the configuration space in a smart way to converge to an optimal configuration, without any human intervention or any knowledge of the application.
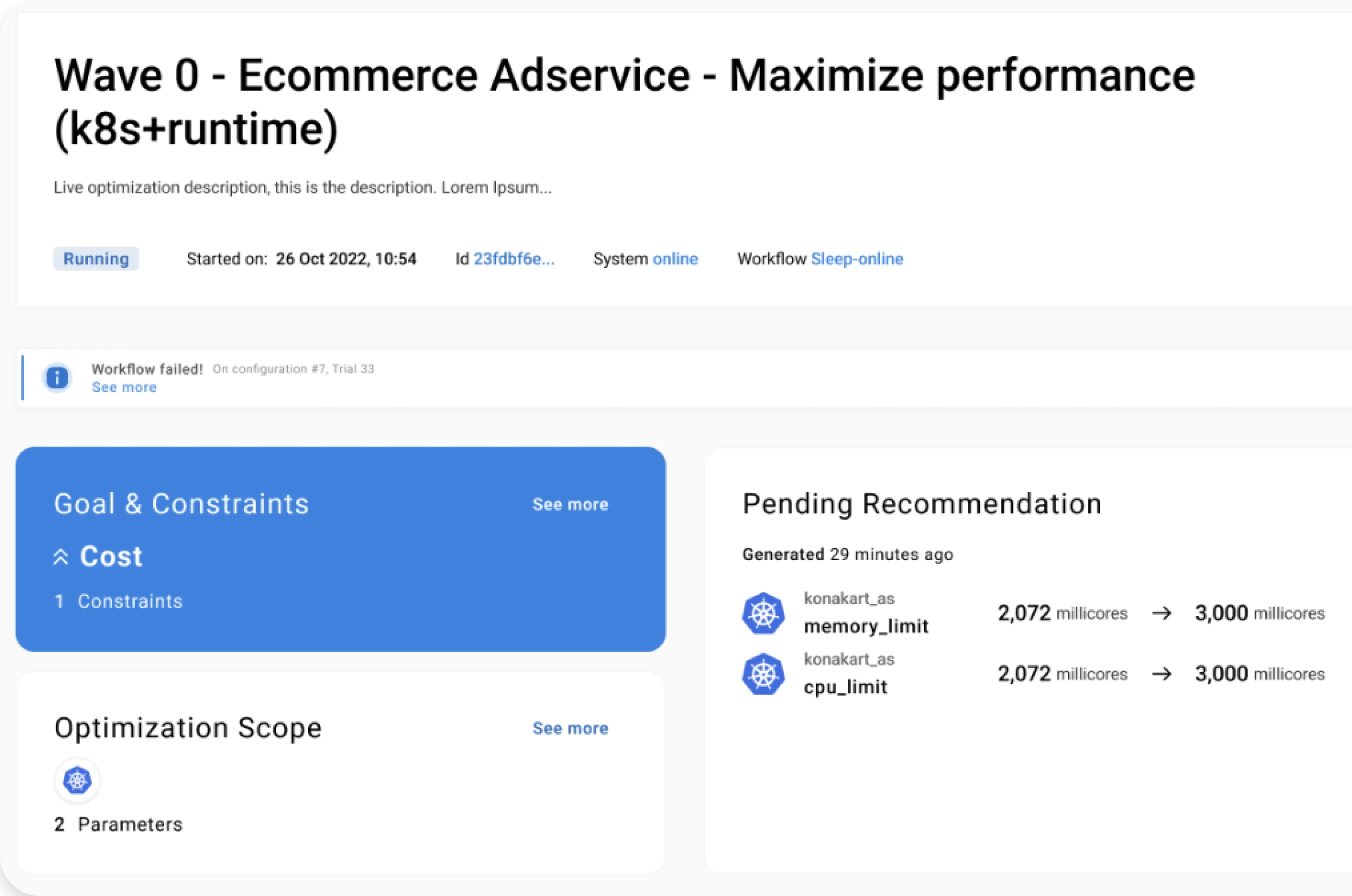
Akamas is the solution based on patented Reinforcement Learning techniques that makes it possible to optimize real-world applications, by considering parameters from multiple layers and technologies and still converging to an optimal configuration in a relatively short time (typically a few hours or days). Thanks to its goal-driven approach, Akamas enables companies to optimize their critical services based on any custom-defined constraints (e.g. SLOs) and goals (e.g. maximize performance or resilience or minimize cost).
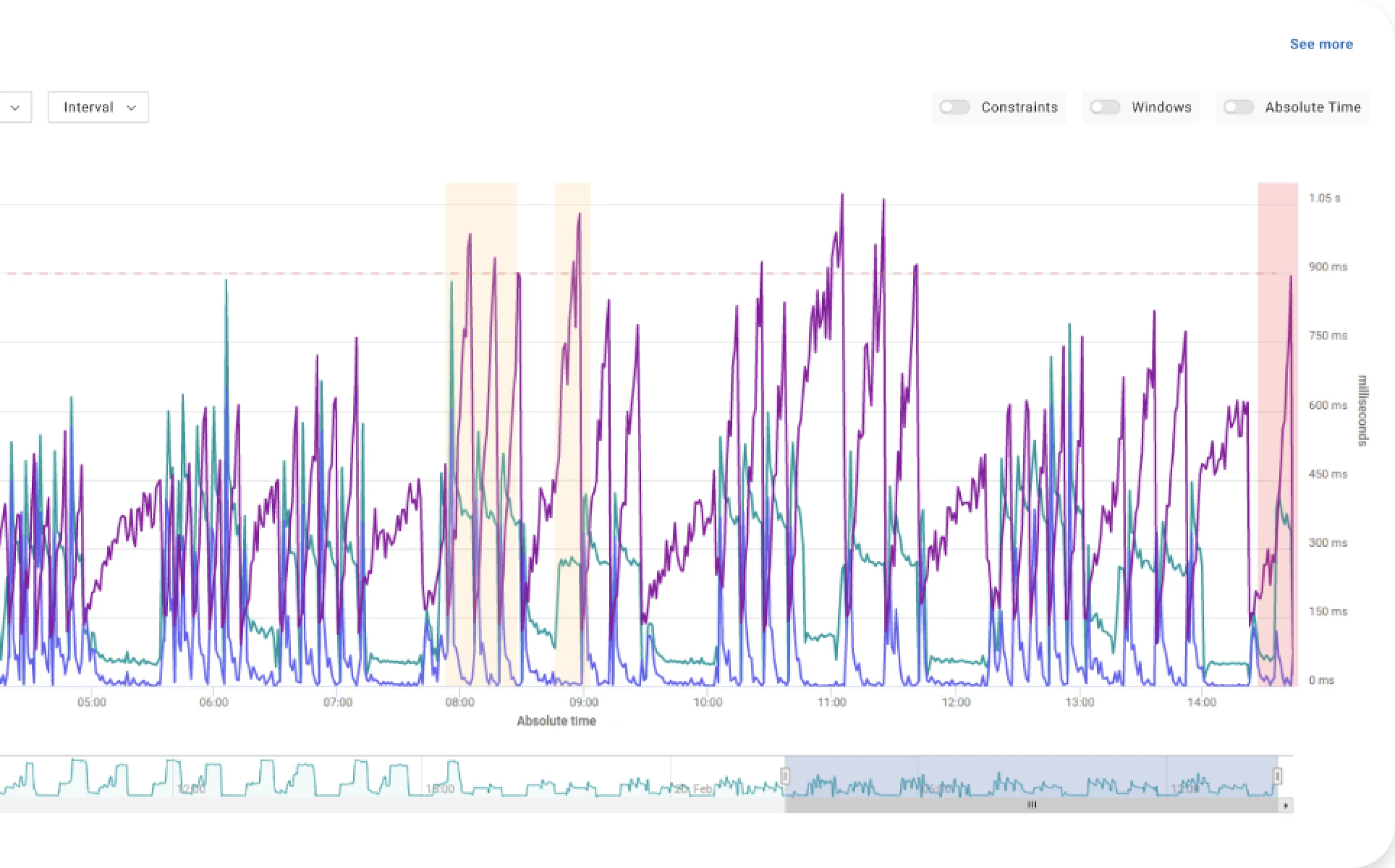
Akamas also support performance engineers and SREs, developers, and service architects in receiving useful insights on potential tradeoffs among competing goals. For example, when Akamas was applied to a microservice providing a critical B2B authorization service, after just a few dozen experiments (about 19 hours) was able to identify a number of better configurations with respect to the given cost reduction goal. The best one would reduce the cloud cost by about 49% while also improving the service response time. Another interesting configuration (found in a shorter time), only slightly reduced the cost (by 16%) but displayed behavior in terms of resilience under higher loads, both in terms of response time and reduced number of triggered replicas.
With Akamas, customers can identify how to apply configurations that either maximize a resilience goal or that can be dynamically applied as a remediation action, in case any specific failure happens.
Conclusions
The combined Chaos Engineering & Autonomous Optimization practice enables customers to achieve higher levels of resilience of their critical services by both identifying failure scenarios and identifying higher-resilience configurations.
By taking advantage of Gremlin and Akamas’ unique capabilities, customers can achieve tangible business benefits such as higher service quality delivered to end-users, better cost-efficiency, and lower operational costs all the while reducing MTTR/MTTD, lowering incident counts, and building a winning culture that keeps reliability and resiliency top of mind.
Keep reading our blog to learn more stories from our customers on the benefits of the combined Chaos Engineering & Autonomous Optimization practice.
Stay tuned!
Authors:


Kyle McMeekin
Head of Channel, Gremlin