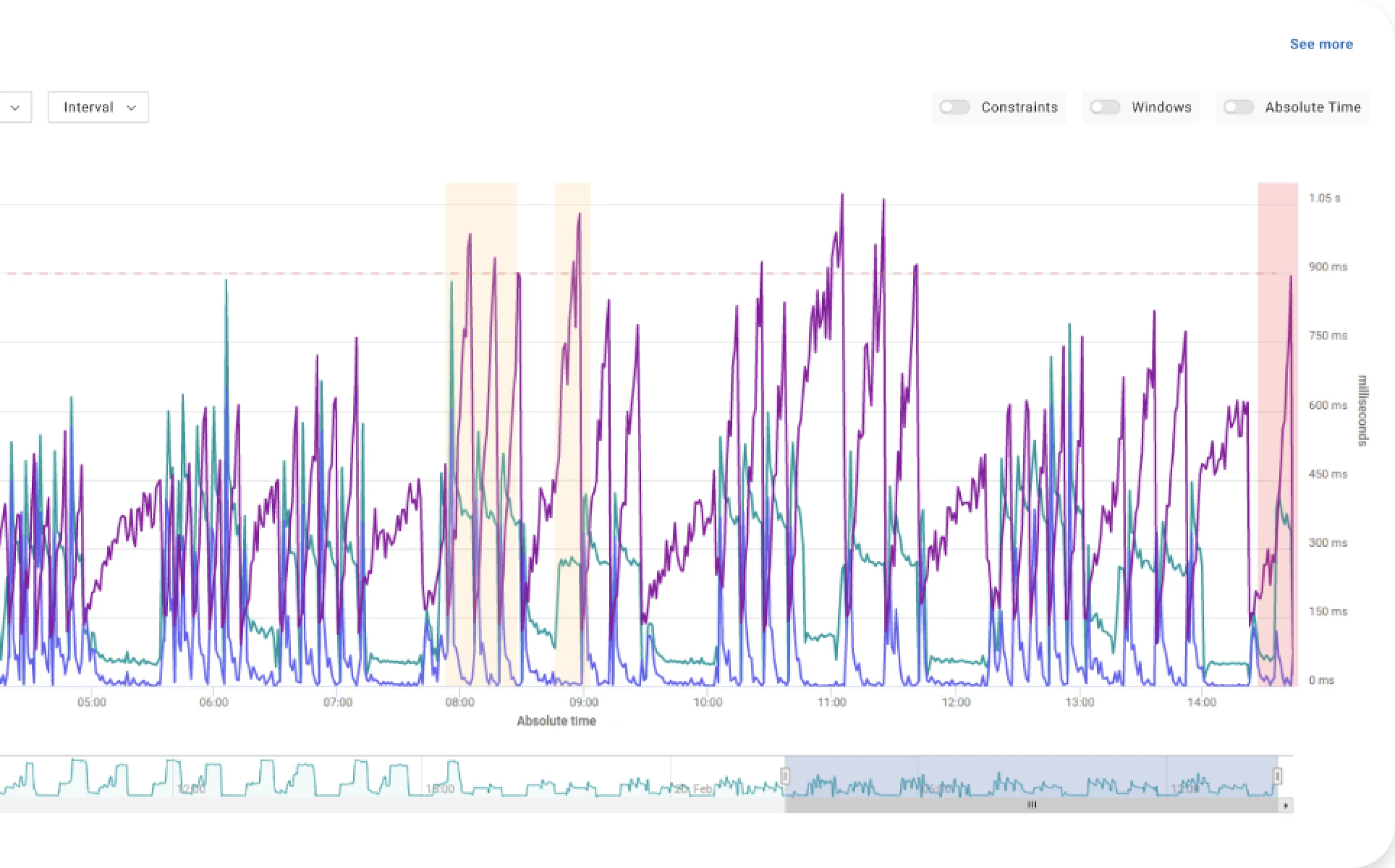
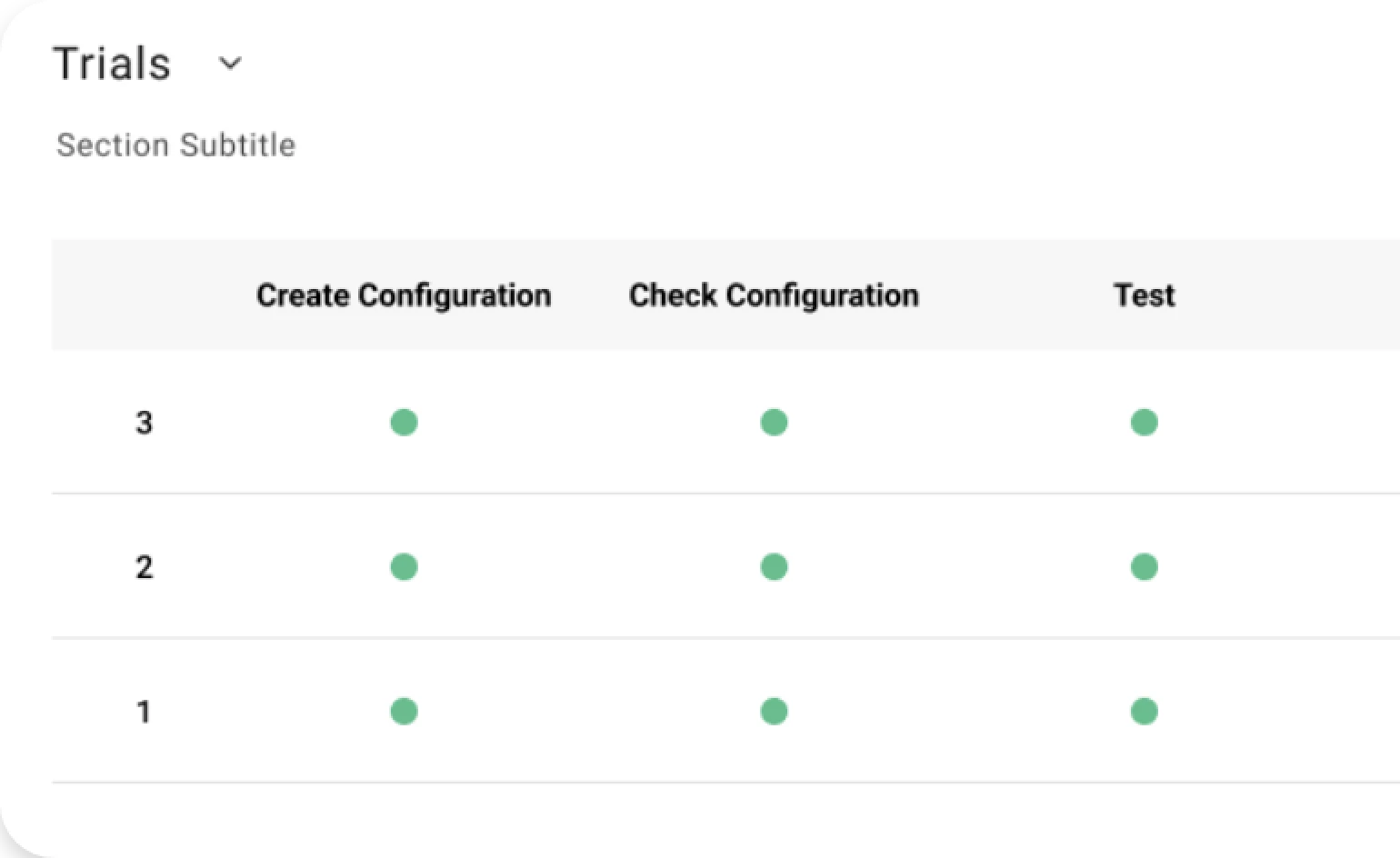
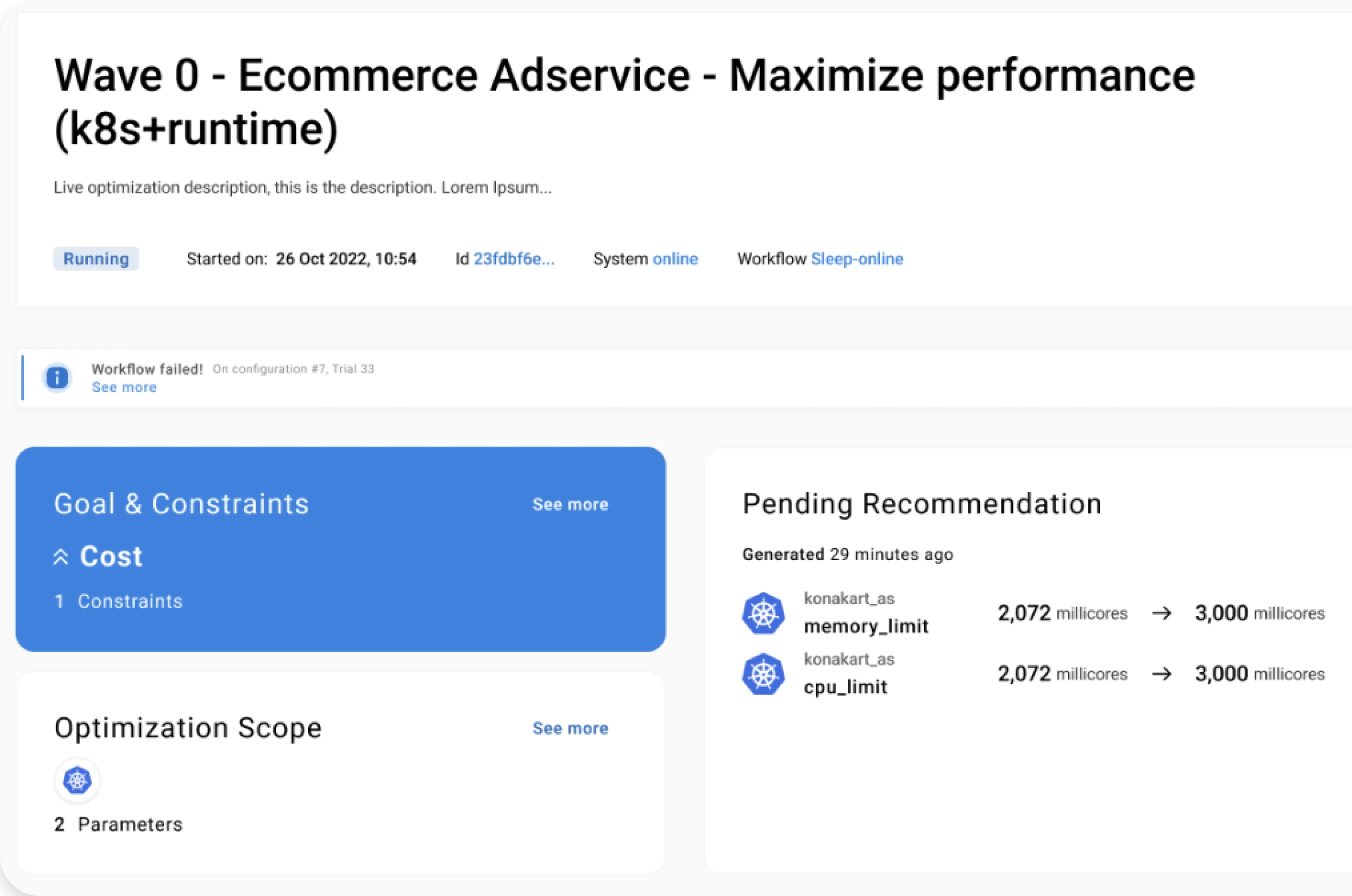
Where:
Online Conference
Start Date:
07 Oct 2020 - 5:00 am CET
End Date:
08 Oct 2020 - 5:00 am CET
Speakers

Luca Cavazzana
Luca is Software Engineer at Akamas. Before joining our team, he was a Technical Solutions Engineer at ContentWise, where he worked to deploy analytics and personalization solutions for some of the largest media and streaming brands worldwide. Luca’s background is in DevOps and cloud infrastructures.